Maybe I’m getting flashbacks of my time in grad school, but reproducibility has been on my mind - I want to make my work as replicable as possible, while at the same time not sacrificing efficiency.
I want to be able to drop and pick up my work whenever and wherever I am
Whether that’s revisiting an old project or using a different machine, I want my work to be highly portable and interoperable . To that end, this post describes the data science set-up that allows me such a workflow. Full disclosure, this might read as an onboarding doc… cause another purpose of this post was to create a checklist if I end up breaking my computer again 😅.
The Problem 🔗
The problem is pretty simple - whatever I’m working on today might work, but next week if I update a package for a different project or if I’m using a new computer, how can I ensure that my code will still work? In other words, how can I manufacture a data science set-up such that I’m forced to create a highly self-contained and portable workflow that I can continually iterate upon.
Text Editors / IDE 🔗
I like to use Atom as my lightweight editor when I’m doing simple changes and I rely on Pycharm if I ever want to build something more robust. Pycharm has great features like merge conflicts and tool-tiping to make sure you remember to do the small but annoying stuff in your code.
Github 🔗
I use GitHub to maintain all my code and notebooks. I have a base folder where I install Jupyter (more on that later) and then within that directory, I have different repositories for my projects. I use SSH to connect to GitHub.
# Create new data directory
Mkdir data
# generate new SSH key
ssh-keygen -t ed25519 -C "your_email@example.com"
# start SSH in the background
eval "$(ssh-agent -s)"
# Open SSH config file
touch ~/.ssh/config
# paste identify file into configuration
Echo ‘Host *.github.com
AddKeysToAgent yes
UseKeychain yes
IdentityFile ~/.ssh/id_ed25519’ >> ~/.ssh/config
# add SSH private key to ssh agent
ssh-add --apple-use-keychain ~/.ssh/id_ed25519
Then add my SSH key in GitHub UI.
#copy public key and paste into Github UI
pbcopy < ~/.ssh/id_ed25519.pub
Maintaining my code in GitHub allows me to 1) make sure that my code exists and is accessible outside of my local machine and 2) create a stable source of truth for my code. At times, I rapidly make changes to my code and things can break. As long as I push code to GitHub consistently I can also revert to a stable state when necessary.
Brew 🔗
Brew installs the packages that macOS is missing.
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
Python Management 🔗
The python version you’re using is important. Different packages interact with and require different python versions. And one small mistake can turn into hours of debugging to see why a once-stable package is misbehaving on your system.
Pyenv allows you to flexibly switch between multiple versions of python by injecting your python version into your path before you start any project or application.
# install pyenv
brew install pyenv
# copy content in pyenv into shell so that pyenv is correctly activated
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zshrc
echo 'command -v pyenv >/dev/null || export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zshrc
echo 'eval "$(pyenv init -)"' >> ~/.zshrc
# restart shell for changes to take affect
exec "$SHELL"
I use python 3.10.0 as my base python version and install it to auto activate in my base data science folder
# install python 3.10.0 to be able to be used by pyenv
pyenv install 3.10.0
# change working directory to base folder
cd ~/data
# create a .python-version in base folder and have python 3.10.0 automatically activated
pyenv local 3.10.0
Poetry 🔗
Package management is by far the worst part of working in Python. I can’t even tell you the countless hours I’ve spent digging through logs to figure out why something suddenly stopped working. And it’s the worst when the reason is that you installed a tiny little package for a completely separate project that caused your entire working environment to become unstable (hence the need for virtual environments, see below).
Poetry is a nice little tool to help resolve this issue. Poetry offers a clean way to maintain package dependencies through a pyproject.toml file while also easily resolving dependency issues.
# install poetry
curl -sSL https://install.python-poetry.org | python3 -
# add poetry path to shell
echo ‘export PATH="/Users/williamkye/.local/bin:$PATH" >> ~/.zshrc
# change to base data science directory
cd ~/data
# initialize poetry
Poetry init
# add jupyterlab to base data science environment
poetry add jupyterlab
Finally, I disable poetry’s virtual environment management functionality and instead manage my virtual environment through pyenv virutalenv.
poetry config virtualenvs.create false
Virtualenv 🔗
I use the pyenv virtualenv wrapper to maintain my virtual environments. For every new project I work on, I spin up a new virtual environment. Virtual environments are important so that projects you work on stay independent of one another and dependencies don’t get entangled. Moreover, a well coupled virtual environment and package management system (poetry) reduces the barriers to anyone being able to pick up and run your code.
# install pyenv-virtualenv
brew install pyenv-virtualenv
# Initialize virtualenv within shell
eval "$(pyenv virtualenv-init -)"
# automatically activate data virtual environment when i’m in base data science folder
Pyenv local data
Note - I don’t completely know why, but for my desired process of maintaining packages via poetry but switching between virtual environments through pyenv virtualenv, I had to install virtualenv after poetry.
Notebook 🔗
Notebooks aren’t perfect, but they are useful for a lot of things. I use notebooks to write most of my blogs (seehugo_nb_exporter and example blog) and to do some quick development. And when/if necessary I elevate my code from notebook form to a package.
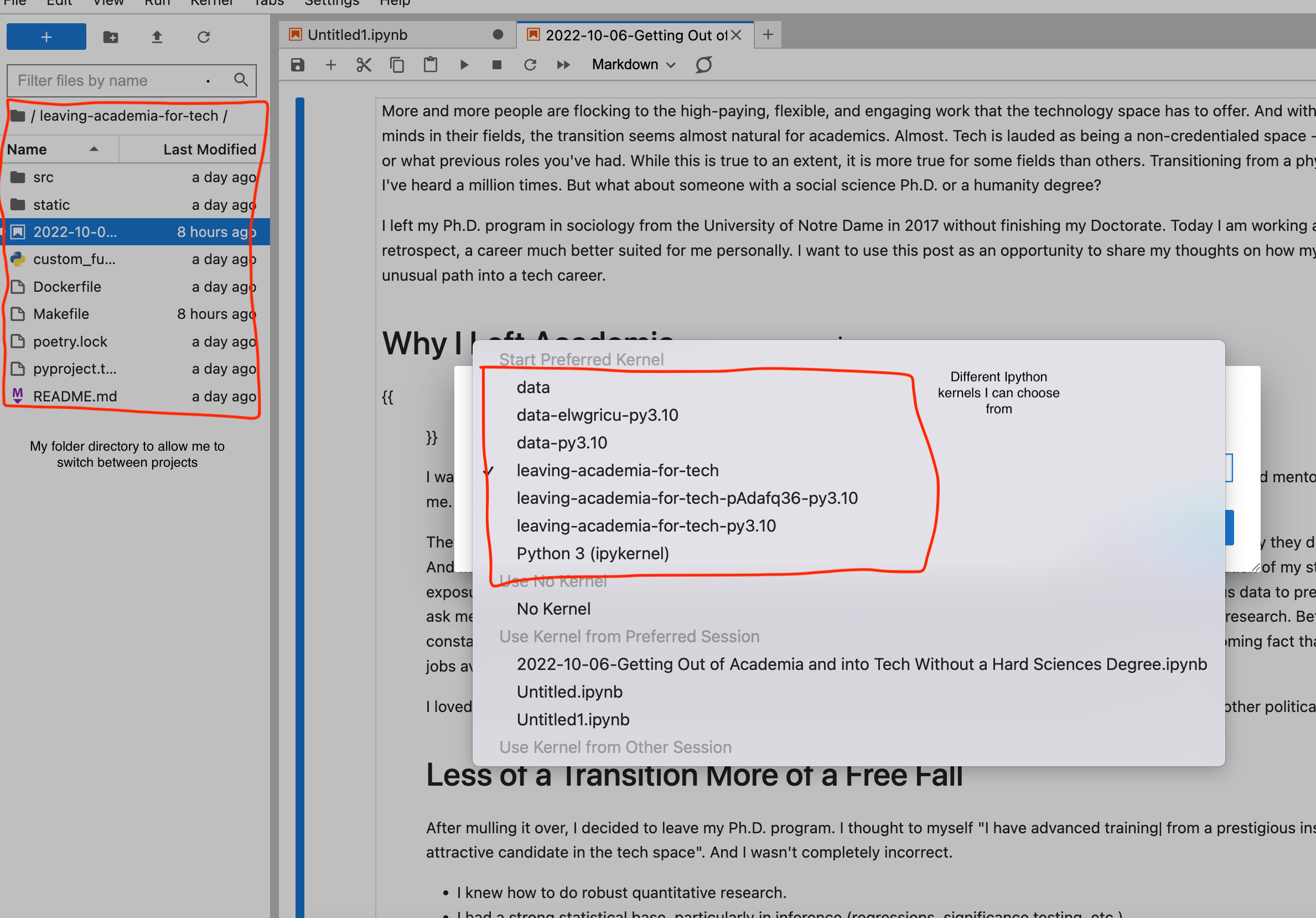
The key for me to be able to work quickly and efficiently is an optimized jupyter set-up. Whether I need to switch between projects (i.e. virtual environments) to see how I did things in the past or whether I need to update a package, I need a centralized way to do development. I’ve found that leveraging jupyter kernels allows me to do so. I have a base folder where jupyter is installed then I switch between project kernels within the UI to allow me to also easily switch between projects
# add ipykernel - this allows a simple way to switch between kernels within jupyter lab
Poetry add ipykernel
python -m ipykernel install --user --name data
# I like to add some basic formatters to my juptyer extension
poetry add jupyterlab-code-formatter
poetry add black isort
Docker 🔗
The ultimate way to have true reproducibility is to use docker to work in a cloud environment. This was just overkill given that my workflow is mainly just for personal projects at this point. But I was interested in learning how to integrate my process with docker in case I wanted to dockerize anything in the future.
Download docker, then create a docker image that caches and installs the requirements from our pyproject.toml and poetry.lock file. Note, a virtual environment is also not necessary in docker, so we do not create one. Do all this within a Dockerfile that is at the same level as your project.
ARG YOUR_ENV
ENV YOUR_ENV=${YOUR_ENV} \
PYTHONFAULTHANDLER=1 \
PYTHONUNBUFFERED=1 \
PYTHONHASHSEED=random \
PIP_NO_CACHE_DIR=off \
PIP_DISABLE_PIP_VERSION_CHECK=on \
PIP_DEFAULT_TIMEOUT=100 \
POETRY_VERSION=1.0.0
# System deps:
RUN pip install "poetry==$POETRY_VERSION"
WORKDIR /<project-name>
COPY . .
# Project initialization:
RUN POETRY_VIRTUALENVS_CREATE=false && poetry install
# Creating folders, and files for a project:
COPY . /code
Then create Makefile that runs your dockerfile
run:
docker build -t wkye/<project-name> .
docker run --rm --name <project-name> \
-v /Users/willie/data/<project-name> \
-p 8888:8888 \
<project-name>
Summary 🔗
Thanks for getting this far! He’s what we covered in this blog
Problem: I needed a way to make my data science work highly portable and easily sharable
Solution:
- Use GitHub as centralized place to maintain stable code .
- Pyenv to allow you to switch between python versions.
- One layer below that, use poetry to allow you to manage your package dependencies.
- Virtualenv allows you to create virtual environment so that your projects can maintain dependency separation.
- Notebooks combined with Ipython kernels allow for quick and efficient switching between environment and notebook within Jupyter.
- If you really want an isolated environment to do your data science work, you can use docker.
If you have any questions or feedback please reach out!